

From the outside, a token launch looks like one event. From the inside, it's four or five systems running simultaneously: sale contracts, staking pools, vesting schedules, claim portals, and community channels. Each piece written by different developers, sometimes from different vendors, all coordinating against the same token at the same time.
That coordination is where launches break. Not inside any one of those systems, but in the seams between them. And those seams are almost always the result of decisions made months earlier, when each piece of the stack was procured or built in isolation.
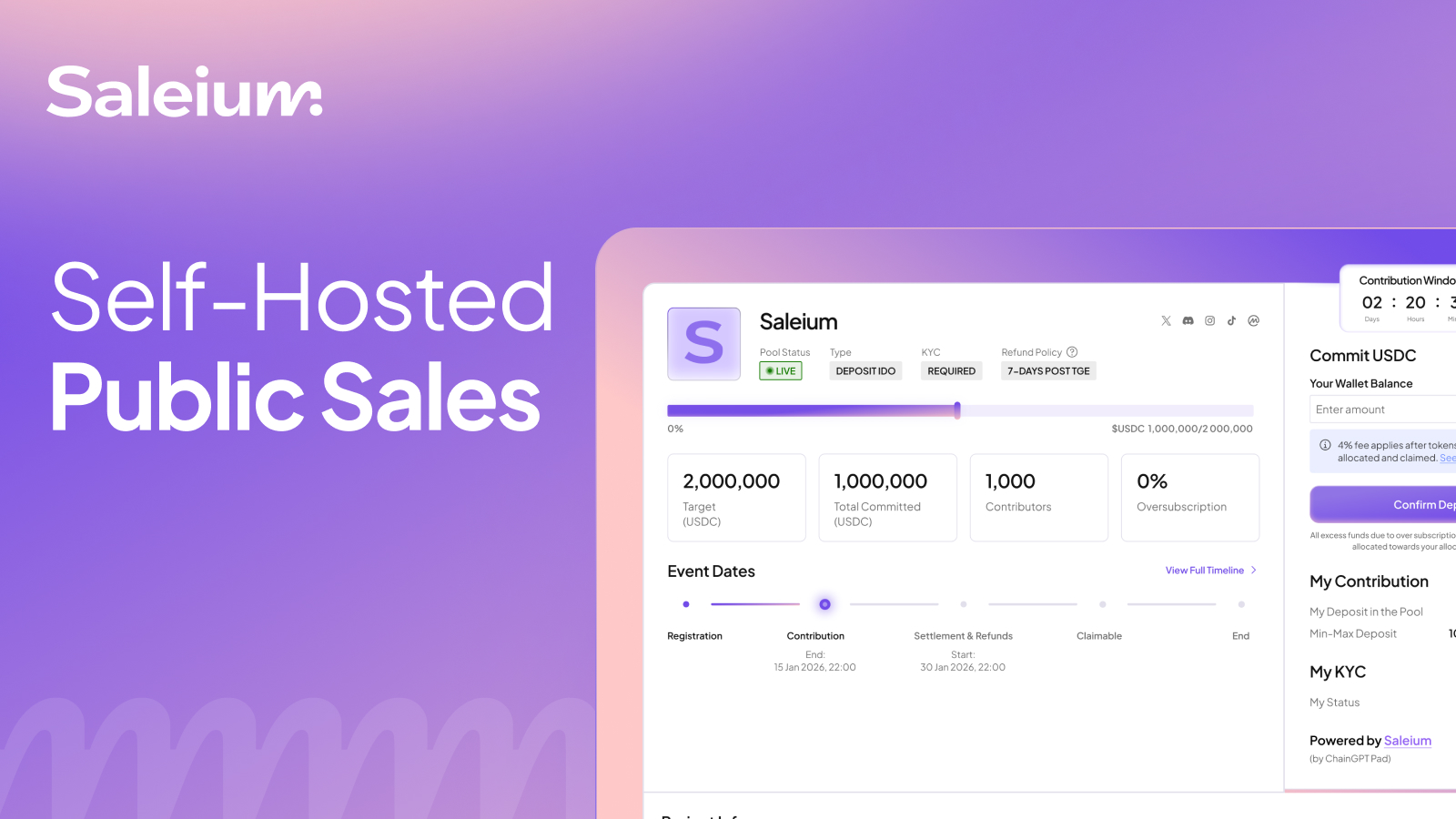
ChainGPT's white-label suite is built as a single integrated stack. The launchpad, staking, vesting, and community AI share the same data model and operate against the same on-chain state, so the seams between them don't exist.
→ Book a demo with the ChainGPT team to see how the white-label suite runs as one stack.
A Launch Is Operated as One Experience, Not Several Products
Participants don't separate the launchpad from the vesting contract from the staking pool. They see one launch and one project. When something breaks, they don't say "the vesting contract failed." They say "the launch was broken."
That perception is what makes integration a launch-day issue, not a roadmap issue. Every breakage between systems shows up to the market as one project failing to deliver, regardless of which vendor or contract caused it. The team owns the experience even when they don't own every piece of it.
Treating the stack as a set of independent products is a mismatch between how teams buy infrastructure and how the market evaluates the outcome.

Disconnection Lives at the Seams
The places where launch infrastructure breaks aren't inside any single tool. They're at the seams between tools.
Staking snapshots taken by one system don't match the allocation logic of the launchpad. Vesting contracts read from a different source of truth than the claim portal. The community bot can't see sale state, so it can't answer the questions flooding in during the launch window. Refund logic doesn't know about staking lockups, so participants get conflicting answers about what they can withdraw and when.
Every additional vendor or in-house module adds another seam. More seams mean more places where the systems can disagree under load, and load is exactly when seams get tested.

Building In-House Multiplies the Seams
Teams that build the stack themselves don't escape the integration problem. They move it inside their own codebase and own every seam by default.
In-house builds still need separate contracts for sale, staking, vesting, and claims. They still need a frontend that surfaces consistent state across all of them. They still need support tooling that knows what every other system is doing at any given moment. The integration work doesn't disappear because the work is internal. It gets added to the launch checklist alongside everything else the engineering team is shipping that quarter.
Most teams underestimate this. "We'll integrate it later" rarely survives launch week, because by the time the seams break, the team running the launch doesn't have the bandwidth to patch contracts in production.
An Integrated Stack Is a Procurement Decision
The teams that ship a launch where the stack talks to itself aren't faster engineers or better integrators. They're teams that made a procurement decision instead of an engineering commitment.
ChainGPT's white-label suite is built so the seams don't exist by design. The launchpad, staking, vesting, and community AI are designed against the same data model and the same on-chain state, deployed together on the project's domain and branded as their own. The integration isn't something the team has to manage post-launch. It's part of what's licensed.
The pre-launch decision to use one integrated stack is the decision to have a launch where every system agrees with every other system on day one, and on every day after.







.png)



















